DeepSeek-R1 demonstruje, dlaczego przyspieszone obliczenia są kluczowe dla AI opierającej się na wnioskowaniu. Proces test-time scaling pozwala modelowi na iteracyjne "myślenie" nad problemem, co prowadzi do generowania większej liczby tokenów i dłuższych cykli generacji, poprawiając jakość odpowiedzi. Większe obliczenia test-time są niezbędne do zapewnienia zarówno natychmiastowej inferencji, jak i wysokiej jakości wyników.
Model R1 osiąga doskonałe wyniki w zadaniach wymagających logiki, matematyki, kodowania oraz rozumienia języka. Wyróżnia się wysoką efektywnością inferencji, co czyni go jednym z najbardziej zaawansowanych modeli w swojej klasie.
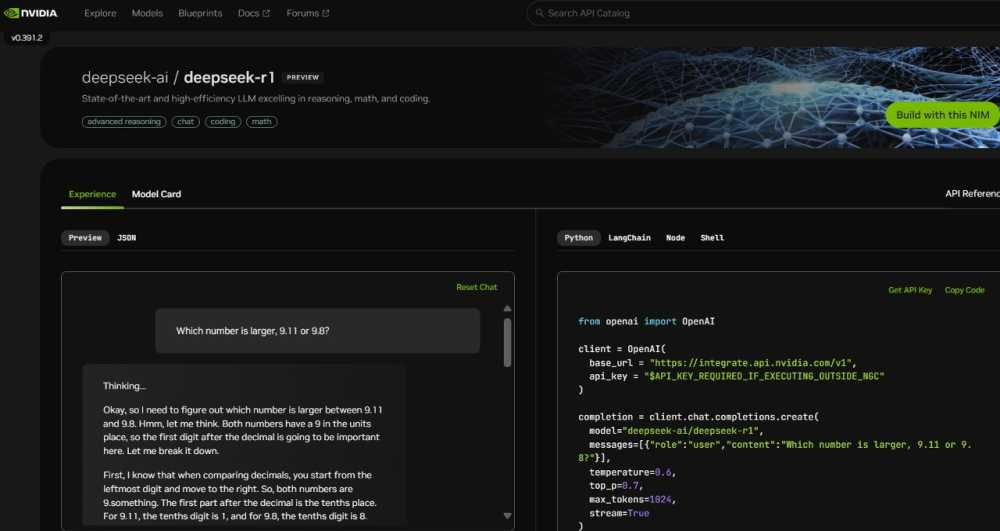
Deweloperzy mogą eksperymentować z tym modelem dzięki udostępnieniu 671-miliardowego DeepSeek-R1 jako mikroserwisu NVIDIA NIM na platformie build.nvidia.com. Usługa ta może dostarczać do 3 872 tokenów na sekundę na pojedynczym systemie NVIDIA HGX H200.
DeepSeek-R1 NIM jest kompatybilny ze standardowymi API, co ułatwia wdrożenia w infrastrukturze obliczeniowej firm. Przedsiębiorstwa mogą uruchamiać mikroserwis w środowiskach zapewniających maksymalne bezpieczeństwo i prywatność danych. W połączeniu z NVIDIA AI Foundry oraz NVIDIA NeMo, możliwa jest dalsza personalizacja DeepSeek-R1 pod kątem specyficznych zastosowań AI.
DeepSeek-R1 to model wykorzystujący architekturę mixture-of-experts (MoE), obejmujący 671 miliardów parametrów, czyli dziesięciokrotnie więcej niż wiele popularnych LLM łatwo dostępnych na rynku. Obsługuje on kontekst wejściowy o długości 128 000 tokenów oraz posiada 256 ekspertów w każdej warstwie, z każdym tokenem przekierowywanym do ośmiu ekspertów równolegle.
Realizacja natychmiastowej inferencji dla DeepSeek-R1 wymaga wielu procesorów graficznych o wysokiej wydajności, połączonych za pomocą NVLink oraz NVLink Switch. Po optymalizacjach NVIDIA NIM, pojedynczy serwer wyposażony w osiem GPU H200 może obsługiwać model DeepSeek-R1 przy przepustowości do 3 872 tokenów na sekundę. Kluczową rolę odgrywa tutaj FP8 Transformer Engine oraz 900 GB/s przepustowości NVLink, umożliwiając sprawną komunikację między ekspertami MoE.
Kolejna generacja architektury NVIDIA Blackwell przyniesie jeszcze większy wzrost wydajności dla modeli takich jak DeepSeek-R1. Piąta generacja Tensor Cores pozwoli na osiągnięcie do 20 petaflopów szczytowej wydajności FP4, a nowa domena NVLink obejmująca 72 GPU zoptymalizuje proces inferencji w modelach wykorzystujących test-time scaling.
Deweloperzy mogą już teraz przetestować mikroserwis DeepSeek-R1 NIM, dostępny na build.nvidia.com. Platforma NVIDIA NIM umożliwia łatwe wdrożenia i zapewnia najwyższą wydajność dla zaawansowanych systemów AI. Warto śledzić rozwój technologii test-time scaling, która może stać się kluczowym elementem przyszłych rozwiązań wnioskowania maszynowego.