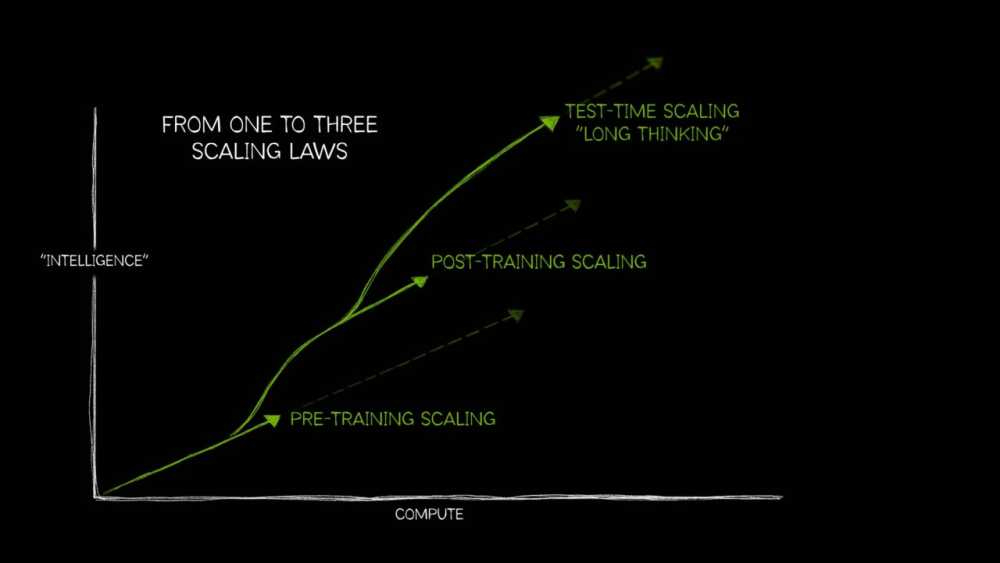
To podstawowe prawo rozwoju AI. Skalowanie wstępne wykazało, że zwiększenie zbioru danych, liczby parametrów modelu oraz zasobów obliczeniowych prowadzi do przewidywalnej poprawy inteligencji i dokładności modelu. Im większy model i im więcej otrzymuje danych, tym lepiej radzi sobie z zadaniami.
Dzięki temu prawu powstały przełomowe modele, w tym gigantyczne modele transformerowe liczone w miliardach i bilionach parametrów. Rosnąca ilość danych multimodalnych (tekst, obrazy, dźwięk, wideo, dane sensoryczne) będzie nadal napędzać rozwój potężniejszych AI.
Nie każda organizacja może pozwolić sobie na wytrenowanie od podstaw ogromnego modelu AI. Jednak już gotowe modele podstawowe mogą być dostosowywane do specyficznych zastosowań dzięki technikom skalowania po treningu.
Wykorzystują one metody takie jak:
Ekosystem modeli pochodnych może wymagać nawet 30 razy większej mocy obliczeniowej niż samo pretrenowanie modelu bazowego. Dzięki temu AI może być lepiej dostosowane do użytkowników, np. w branży medycznej, finansowej czy prawniczej.
Tradycyjne modele AI generują szybkie odpowiedzi, ale mogą mieć problem z bardziej skomplikowanymi zadaniami wymagającymi rozumowania. Skalowanie w czasie testu pozwala modelom na zastosowanie większych mocy obliczeniowych podczas generowania odpowiedzi, co umożliwia im wieloetapowe myślenie.
Podstawowe techniki test-time scaling to:
Modele AI, takie jak OpenAI o1-mini, DeepSeek R1 czy Gemini 2.0, już teraz wykorzystują te techniki do poprawy jakości odpowiedzi. Skalowanie w czasie testu wymaga jednak ogromnych zasobów obliczeniowych – dla skomplikowanych zapytań może pochłaniać nawet 100 razy więcej mocy niż standardowe jednoprzebiegowe generowanie odpowiedzi.
Nowoczesne modele AI wymagają coraz większej mocy obliczeniowej do skutecznego rozumowania. Skalowanie w czasie testu może być kluczem do budowy zaawansowanych agentów AI zdolnych do samodzielnego planowania i podejmowania decyzji w rzeczywistym świecie.